L'abstraction des données est une technique de programmation (qui n'est pas propre à la programmation fonctionnelle) et qui consiste à manipuler des données définies de manière abstraite indépendamment de la façon dont elles sont implantées.
Pour bien programmer un problème, on doit passer par plusieurs étapes :

La phase d'analyse fait apparaître une certain nombre de classes d'objets que l'on va devoir manipuler ainsi que les opérations qui leurs sont associées. Par exemple des ensembles et les opérations d'union, d'intersection, etc... ou bien des listes et les opérations élémentaires cons, car, cdr.
Ce sont ces classes d'objets qui constituent des types abstrait de données .
![\fbox{
\begin{minipage}{12cm}
Un {\bf type abstrait de donn\'ees}, c'est :
\begi...
...ets
\item[-] des fonctions op\'erant sur ces objets
\end{itemize}\end{minipage}}](img86.gif)
Un type de données peut être prédéfini dans le langage de programmation utilisé, auquel cas on parle de type de base.
Ex :
Si c'est un type que l'on définit, on parle de type abstrait de données (TAD).
On définit un type de données abstrait ![]() en décrivant le profil des fonctions pour lesquelles le type
en décrivant le profil des fonctions pour lesquelles le type ![]() entre en jeu. Ces fonctions admettent un certain nombre (éventuellement 0) de paramètres et fournissent un résultat. Le profil d'une fonction doit faire apparaître les types des paramètres et du résultat :
entre en jeu. Ces fonctions admettent un certain nombre (éventuellement 0) de paramètres et fournissent un résultat. Le profil d'une fonction doit faire apparaître les types des paramètres et du résultat :
On peut diviser les fonctions d'un TAD en deux classes (pas forcément disjointes) :
Parmi les fonctions dont le résultat est de type ![]() ,
on distingue celles qui permettent d'engendrer tous les objets de type
,
on distingue celles qui permettent d'engendrer tous les objets de type ![]() et que l'on appelle fonctions génératrices de
et que l'on appelle fonctions génératrices de ![]() .
.
De même parmi les fonctions dont un des paramètres est de type ![]() on en distingue certaines que l'on appelle fonctions caractéristiques de
on en distingue certaines que l'on appelle fonctions caractéristiques de ![]() .
.
Les génératrices et les caractéristiques forment un ensemble minimal de fonctions à partir desquelles on définit toutes les autres fonctions opérant sur ou dans ![]() .
.
On peut spécifier des axiomes liant ces fonctions, ce qui permet de démontrer des propriétés de programme.
Ex :
On définit le TAD ![]() des listes plates finies d'entiers de la manière suivante :
des listes plates finies d'entiers de la manière suivante :
| génératrices de |
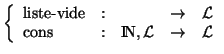 |
| caractéristiques de |
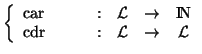 |
Axiome :
![]()
Quand on utilise un TAD on ne prend pas en compte les détails de son implantation. En d'autres termes, les algorithmes résultant de l'analyse de la spécification utilisent uniquement les fonctions génératrices et caractéristiques et les autres fonctions relatives au TAD ![]() .
.
Le programme résultant du codage respecte l'abstraction des données, c'est à dire qu'on distingue bien deux parties :
Cette technique de programmation offre deux avantages :
On définit le TAD doublet (d'entiers naturels) dont les profils des fonctions génératrices et caractéristiques sont :
Connaissant le profil de ces fonctions, on peut écrire un programme utilisant le TAD doublet qui est complètement indépendant de toute implantation ;
; programme utilisant le TAD doublet
(define symetrique (lambda (d)
(cons-doublet (second d) (premier d))))
(define egal-doublet? (lambda (d1 d2)
(and (= (premier d1) (premier d2))
(= (second d1) (second d2)) ))
Et voici deux implantations possibles du TAD doublets :
; 1ere implantation fondee sur les listes
(define cons-doublet
(lambda (a b)(list a b)) )
(define premier
(lambda (d) (car d)))
(define second
(lambda (d) (cadr p)))
; 2eme implantation fondee sur les entiers
(define cons-doublet
(lambda (a b) (* (expt 2 a) (expt 3 b)) ))
(define premier (lambda (d)
(define premier-aux
(lambda (d1 n)
(let ( (q (quotient d1 2))
(r (remainder d1 2)) )
(if (not (= r 0))
n
(premier-aux q (+ n 1))))))
(premier-aux d 0) ))
(define second (lambda (d)
(define second-aux
(lambda (d1 n)
(let ( (q (quotient d1 3))
(r (remainder d1 3)) )
(if (not (= r 0))
n
(second-aux q (+ n 1))))))
(second-aux d 0) ))
Implantation à l'aide de listes :
(define pile-vide
(lambda () '()))
(define empiler
(lambda (x p) (cons x p)))
(define sommet
(lambda (p) (car p)))
(define depiler
(lambda (p) (cdr p)))
(define pile-vide?
(lambda (p) (equal? p '())))
Implantation à l'aide de listes :
(define file-vide
(lambda (f) '()))
(define enfiler
(lambda (x f) (append f (cons x '())) ))
(define tete
(lambda (f) (car f)))
(define defiler
(lambda (f) (cdr f)))
(define file-vide?
(lambda (f) (equal? f '())))